Relational model
The relational model for database management is a database model based on first-order predicate logic, first formulated and proposed in 1969 by Edgar F. Codd.[1][2][3]


The purpose of the relational model is to provide a declarative method for specifying data and queries: users directly state what information the database contains and what information they want from it, and let the database management system software take care of describing data structures for storing the data and retrieval procedures for answering queries.
IBM's original implementation of Codd's ideas was System R. There have been several commercial and open source products (relational database management systems) based on Codd's ideas, including IBM's DB2, Sybase Adaptive Server Enterprise (ASE), Oracle Database, Microsoft SQL Server, PostgreSQL, MySQL, and many others. Most of these use the SQL data definition and query language. A table in an SQL database schema corresponds to a predicate variable; the contents of a table to a relation; key constraints, other constraints, and SQL queries correspond to predicates. However, SQL databases, including DB2, deviate from the relational model in many details; Codd fiercely argued against deviations that compromise the original principles.[5]
Contents |
[edit] Overview
The relational model's central idea is to describe a database as a collection of predicates over a finite set of predicate variables, describing constraints on the possible values and combinations of values. The content of the database at any given time is a finite (logical) model of the database, i.e. a set of relations, one per predicate variable, such that all predicates are satisfied. A request for information from the database (a database query) is also a predicate.

[edit] Alternatives to the relational model
Other models are the hierarchical model and network model. Some systems using these older architectures are still in use today in data centers with high data volume needs, or where existing systems are so complex and abstract it would be cost-prohibitive to migrate to systems employing the relational model; also of note are newer object-oriented databases.
A recent development is the Object-Relation type-Object model, which is based on the assumption that any fact can be expressed in the form of one or more binary relationships. The model is used in Object Role Modeling (ORM), RDF/Notation 3 (N3).
The relational model was the first database model to be described in formal mathematical terms. Hierarchical and network databases existed before relational databases, but their specifications were relatively informal. After the relational model was defined, there were many attempts to compare and contrast the different models, and this led to the emergence of more rigorous descriptions of the earlier models; though the procedural nature of the data manipulation interfaces for hierarchical and network databases limited the scope for formalization.
[edit] Implementation
There have been several attempts to produce a true implementation of the relational database model as originally defined by Codd and explained by Date, Darwen and others, but none have been popular successes so far. Rel is one of the more recent attempts to do this.
[edit] History
The relational model was invented by E.F. (Ted) Codd as a general model of data, and subsequently maintained and developed by Chris Date and Hugh Darwen among others. In The Third Manifesto (first published in 1995) Date and Darwen show how the relational model can accommodate certain desired object-oriented features.
[edit] Controversies
Codd himself, some years after publication of his 1970 model, proposed a three-valued logic (True, False, Missing or NULL) version of it to deal with missing information, and in his The Relational Model for Database Management Version 2 (1990) he went a step further with a four-valued logic (True, False, Missing but Applicable, Missing but Inapplicable) version. But these have never been implemented, presumably because of attending complexity. SQL's NULL construct was intended to be part of a three-valued logic system, but fell short of that due to logical errors in the standard and in its implementations.[citation needed]
[edit] Relational model topics
[edit] The model
The fundamental assumption of the relational model is that all data is represented as mathematical n-ary relations, an n-ary relation being a subset of the Cartesian product of n domains. In the mathematical model, reasoning about such data is done in two-valued predicate logic, meaning there are two possible evaluations for each proposition: either true or false (and in particular no third value such as unknown, or not applicable, either of which are often associated with the concept of NULL). Data are operated upon by means of a relational calculus or relational algebra, these being equivalent in expressive power.
The relational model of data permits the database designer to create a consistent, logical representation of information. Consistency is achieved by including declared constraints in the database design, which is usually referred to as the logical schema. The theory includes a process of database normalization whereby a design with certain desirable properties can be selected from a set of logically equivalent alternatives. The access plans and other implementation and operation details are handled by the DBMS engine, and are not reflected in the logical model. This contrasts with common practice for SQL DBMSs in which performance tuning often requires changes to the logical model.
The basic relational building block is the domain or data type, usually abbreviated nowadays to type. A tuple is an ordered set of attribute values. An attribute is an ordered pair of attribute name and type name. An attribute value is a specific valid value for the type of the attribute. This can be either a scalar value or a more complex type.
A relation consists of a heading and a body. A heading is a set of attributes. A body (of an n-ary relation) is a set of n-tuples. The heading of the relation is also the heading of each of its tuples.
A relation is defined as a set of n-tuples. In both mathematics and the relational database model, a set is an unordered collection of unique, non-duplicated items, although some DBMSs impose an order to their data. In mathematics, a tuple has an order, and allows for duplication. E.F. Codd originally defined tuples using this mathematical definition.[6] Later, it was one of E.F. Codd's great insights that using attribute names instead of an ordering would be so much more convenient (in general) in a computer language based on relations[citation needed]. This insight is still being used today. Though the concept has changed, the name "tuple" has not. An immediate and important consequence of this distinguishing feature is that in the relational model the Cartesian product becomes commutative.
A table is an accepted visual representation of a relation; a tuple is similar to the concept of row, but note that in the database language SQL the columns and the rows of a table are ordered.[citation needed]
A relvar is a named variable of some specific relation type, to which at all times some relation of that type is assigned, though the relation may contain zero tuples.
The basic principle of the relational model is the Information Principle: all information is represented by data values in relations. In accordance with this Principle, a relational database is a set of relvars and the result of every query is presented as a relation.
The consistency of a relational database is enforced, not by rules built into the applications that use it, but rather by constraints, declared as part of the logical schema and enforced by the DBMS for all applications. In general, constraints are expressed using relational comparison operators, of which just one, "is subset of" (⊆), is theoretically sufficient[citation needed]. In practice, several useful shorthands are expected to be available, of which the most important are candidate key (really, superkey) and foreign key constraints.
[edit] Interpretation
To fully appreciate the relational model of data it is essential to understand the intended interpretation of a relation.
The body of a relation is sometimes called its extension. This is because it is to be interpreted as a representation of the extension of some predicate, this being the set of true propositions that can be formed by replacing each free variable in that predicate by a name (a term that designates something).
There is a one-to-one correspondence between the free variables of the predicate and the attribute names of the relation heading. Each tuple of the relation body provides attribute values to instantiate the predicate by substituting each of its free variables. The result is a proposition that is deemed, on account of the appearance of the tuple in the relation body, to be true. Contrariwise, every tuple whose heading conforms to that of the relation but which does not appear in the body is deemed to be false. This assumption is known as the closed world assumption: it is often violated in practical databases, where the absence of a tuple might mean that the truth of the corresponding proposition is unknown. For example, the absence of the tuple ('John', 'Spanish') from a table of language skills cannot necessarily be taken as evidence that John does not speak Spanish.
For a formal exposition of these ideas, see the section Set-theoretic Formulation, below.
[edit] Application to databases
A data type as used in a typical relational database might be the set of integers, the set of character strings, the set of dates, or the two boolean values true and false, and so on. The corresponding type names for these types might be the strings "int", "char", "date", "boolean", etc. It is important to understand, though, that relational theory does not dictate what types are to be supported; indeed, nowadays provisions are expected to be available for user-defined types in addition to the built-in ones provided by the system.
Attribute is the term used in the theory for what is commonly referred to as a column. Similarly, table is commonly used in place of the theoretical term relation (though in SQL the term is by no means synonymous with relation). A table data structure is specified as a list of column definitions, each of which specifies a unique column name and the type of the values that are permitted for that column. An attribute value is the entry in a specific column and row, such as "John Doe" or "35".
A tuple is basically the same thing as a row, except in an SQL DBMS, where the column values in a row are ordered. (Tuples are not ordered; instead, each attribute value is identified solely by the attribute name and never by its ordinal position within the tuple.) An attribute name might be "name" or "age".
A relation is a table structure definition (a set of column definitions) along with the data appearing in that structure. The structure definition is the heading and the data appearing in it is the body, a set of rows. A database relvar (relation variable) is commonly known as a base table. The heading of its assigned value at any time is as specified in the table declaration and its body is that most recently assigned to it by invoking some update operator (typically, INSERT, UPDATE, or DELETE). The heading and body of the table resulting from evaluation of some query are determined by the definitions of the operators used in the expression of that query. (Note that in SQL the heading is not always a set of column definitions as described above, because it is possible for a column to have no name and also for two or more columns to have the same name. Also, the body is not always a set of rows because in SQL it is possible for the same row to appear more than once in the same body.)
[edit] SQL and the relational model
SQL, initially pushed as the standard language for relational databases, deviates from the relational model in several places. The current ISO SQL standard doesn't mention the relational model or use relational terms or concepts. However, it is possible to create a database conforming to the relational model using SQL if one does not use certain SQL features.
The following deviations from the relational model have been noted[who?] in SQL. Note that few database servers implement the entire SQL standard and in particular do not allow some of these deviations. Whereas NULL is ubiquitous, for example, allowing duplicate column names within a table or anonymous columns is uncommon.
- Duplicate rows
- The same row can appear more than once in an SQL table. The same tuple cannot appear more than once in a relation.
- Anonymous columns
- A column in an SQL table can be unnamed and thus unable to be referenced in expressions. The relational model requires every attribute to be named and referenceable.
- Duplicate column names
- Two or more columns of the same SQL table can have the same name and therefore cannot be referenced, on account of the obvious ambiguity. The relational model requires every attribute to be referenceable.
- Column order significance
- The order of columns in an SQL table is defined and significant, one consequence being that SQL's implementations of Cartesian product and union are both noncommutative. The relational model requires there to be no significance to any ordering of the attributes of a relation.
- Views without CHECK OPTION
- Updates to a view defined without CHECK OPTION can be accepted but the resulting update to the database does not necessarily have the expressed effect on its target. For example, an invocation of INSERT can be accepted but the inserted rows might not all appear in the view, or an invocation of UPDATE can result in rows disappearing from the view. The relational model requires updates to a view to have the same effect as if the view were a base relvar.
- Columnless tables unrecognized
- SQL requires every table to have at least one column, but there are two relations of degree zero (of cardinality one and zero) and they are needed to represent extensions of predicates that contain no free variables.
- NULL
- This special mark can appear instead of a value wherever a value can appear in SQL, in particular in place of a column value in some row. The deviation from the relational model arises from the fact that the implementation of this ad hoc concept in SQL involves the use of three-valued logic, under which the comparison of NULL with itself does not yield true but instead yields the third truth value, unknown; similarly the comparison NULL with something other than itself does not yield false but instead yields unknown. It is because of this behaviour in comparisons that NULL is described as a mark rather than a value. The relational model depends on the law of excluded middle under which anything that is not true is false and anything that is not false is true; it also requires every tuple in a relation body to have a value for every attribute of that relation. This particular deviation is disputed by some if only because E.F. Codd himself eventually advocated the use of special marks and a 4-valued logic, but this was based on his observation that there are two distinct reasons why one might want to use a special mark in place of a value, which led opponents of the use of such logics to discover more distinct reasons and at least as many as 19 have been noted, which would require a 21-valued logic.[citation needed] SQL itself uses NULL for several purposes other than to represent "value unknown". For example, the sum of the empty set is NULL, meaning zero, the average of the empty set is NULL, meaning undefined, and NULL appearing in the result of a LEFT JOIN can mean "no value because there is no matching row in the right-hand operand".
[edit] Relational operations
Users (or programs) request data from a relational database by sending it a query that is written in a special language, usually a dialect of SQL. Although SQL was originally intended for end-users, it is much more common for SQL queries to be embedded into software that provides an easier user interface. Many web sites, such as Wikipedia, perform SQL queries when generating pages.
In response to a query, the database returns a result set, which is just a list of rows containing the answers. The simplest query is just to return all the rows from a table, but more often, the rows are filtered in some way to return just the answer wanted.
Often, data from multiple tables are combined into one, by doing a join. Conceptually, this is done by taking all possible combinations of rows (the Cartesian product), and then filtering out everything except the answer. In practice, relational database management systems rewrite ("optimize") queries to perform faster, using a variety of techniques.
There are a number of relational operations in addition to join. These include project (the process of eliminating some of the columns), restrict (the process of eliminating some of the rows), union (a way of combining two tables with similar structures), difference (which lists the rows in one table that are not found in the other), intersect (which lists the rows found in both tables), and product (mentioned above, which combines each row of one table with each row of the other). Depending on which other sources you consult, there are a number of other operators – many of which can be defined in terms of those listed above. These include semi-join, outer operators such as outer join and outer union, and various forms of division. Then there are operators to rename columns, and summarizing or aggregating operators, and if you permit relation values as attributes (RVA – relation-valued attribute), then operators such as group and ungroup. The SELECT statement in SQL serves to handle all of these except for the group and ungroup operators.
The flexibility of relational databases allows programmers to write queries that were not anticipated by the database designers. As a result, relational databases can be used by multiple applications in ways the original designers did not foresee, which is especially important for databases that might be used for a long time (perhaps several decades). This has made the idea and implementation of relational databases very popular with businesses.
[edit] Database normalization
Relations are classified based upon the types of anomalies to which they're vulnerable. A database that's in the first normal form is vulnerable to all types of anomalies, while a database that's in the domain/key normal form has no modification anomalies. Normal forms are hierarchical in nature. That is, the lowest level is the first normal form, and the database cannot meet the requirements for higher level normal forms without first having met all the requirements of the lesser normal forms.[7]
[edit] Examples
[edit] Database
An idealized, very simple example of a description of some relvars (relation variables) and their attributes:
- Customer (Customer ID, Tax ID, Name, Address, City, State, Zip, Phone, Email)
- Order (Order No, Customer ID, Invoice No, Date Placed, Date Promised, Terms, Status)
- Order Line (Order No, Order Line No, Product Code, Qty)
- Invoice (Invoice No, Customer ID, Order No, Date, Status)
- Invoice Line (Invoice No, Invoice Line No, Product Code, Qty Shipped)
- Product (Product Code, Product Description)
In this design we have six relvars: Customer, Order, Order Line, Invoice, Invoice Line and Product. The bold, underlined attributes are candidate keys. The non-bold, underlined attributes are foreign keys.
Usually one candidate key is arbitrarily chosen to be called the primary key and used in preference over the other candidate keys, which are then called alternate keys.
A candidate key is a unique identifier enforcing that no tuple will be duplicated; this would make the relation into something else, namely a bag, by violating the basic definition of a set. Both foreign keys and superkeys (which includes candidate keys) can be composite, that is, can be composed of several attributes. Below is a tabular depiction of a relation of our example Customer relvar; a relation can be thought of as a value that can be attributed to a relvar.
[edit] Customer relation
Customer ID Tax ID Name Address [More fields....] ================================================================================================== 1234567890 555-5512222 Munmun 323 Broadway ... 2223344556 555-5523232 Wile E. 1200 Main Street ... 3334445563 555-5533323 Ekta 871 1st Street ... 4232342432 555-5325523 E. F. Codd 123 It Way ...
If we attempted to insert a new customer with the ID 1234567890, this would violate the design of the relvar since Customer ID is a primary key and we already have a customer 1234567890. The DBMS must reject a transaction such as this that would render the database inconsistent by a violation of an integrity constraint.
Foreign keys are integrity constraints enforcing that the value of the attribute set is drawn from a candidate key in another relation. For example in the Order relation the attribute Customer ID is a foreign key. A join is the operation that draws on information from several relations at once. By joining relvars from the example above we could query the database for all of the Customers, Orders, and Invoices. If we only wanted the tuples for a specific customer, we would specify this using a restriction condition.
If we wanted to retrieve all of the Orders for Customer 1234567890, we could query the database to return every row in the Order table with Customer ID 1234567890 and join the Order table to the Order Line table based on Order No.
There is a flaw in our database design above. The Invoice relvar contains an Order No attribute. So, each tuple in the Invoice relvar will have one Order No, which implies that there is precisely one Order for each Invoice. But in reality an invoice can be created against many orders, or indeed for no particular order. Additionally the Order relvar contains an Invoice No attribute, implying that each Order has a corresponding Invoice. But again this is not always true in the real world. An order is sometimes paid through several invoices, and sometimes paid without an invoice. In other words there can be many Invoices per Order and many Orders per Invoice. This is a many-to-many relationship between Order and Invoice (also called a non-specific relationship). To represent this relationship in the database a new relvar should be introduced whose role is to specify the correspondence between Orders and Invoices:
OrderInvoice(Order No,Invoice No)
Now, the Order relvar has a one-to-many relationship to the OrderInvoice table, as does the Invoice relvar. If we want to retrieve every Invoice for a particular Order, we can query for all orders where Order No in the Order relation equals the Order No in OrderInvoice, and where Invoice No in OrderInvoice equals the Invoice No in Invoice.
[edit] Set-theoretic formulation
Basic notions in the relational model are relation names
and attribute names. We will represent these as strings such as "Person"
and "name" and we will usually use the variables 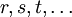 and
and 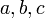 to
range over them. Another basic notion is the set of atomic values that
contains values such as numbers and strings.
to
range over them. Another basic notion is the set of atomic values that
contains values such as numbers and strings.
Our first definition concerns the notion of tuple, which formalizes the notion of row or record in a table:
- Tuple
- A tuple is a partial function from attribute names to atomic values.
- Header
- A header is a finite set of attribute names.
- Projection
- The projection of a tuple
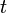 on a finite set of attributes
on a finite set of attributes
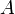 is
is ![t[A] = \{ (a, v) : (a, v) \in t, a \in A \}](relation1_files/2a802f80bd61d925898634fbffb59277.png) .
.
The next definition defines relation which formalizes the contents of a table as it is defined in the relational model.
- Relation
- A relation is a tuple
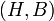 with
with 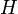 ,
the header, and
,
the header, and 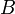 ,
the body, a set of tuples that all have the domain .
,
the body, a set of tuples that all have the domain .
Such a relation closely corresponds to what is usually called the extension of a predicate in first-order logic except that here we identify the places in the predicate with attribute names. Usually in the relational model a database schema is said to consist of a set of relation names, the headers that are associated with these names and the constraints that should hold for every instance of the database schema.
- Relation universe
- A relation universe
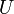 over a header
is a non-empty set of relations with header .
over a header
is a non-empty set of relations with header . - Relation schema
- A relation schema
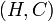 consists of a header
and a predicate
consists of a header
and a predicate 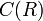 that is defined for all relations
that is defined for all relations 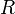 with header .
A relation satisfies a relation schema
if it has header
and satisfies
with header .
A relation satisfies a relation schema
if it has header
and satisfies 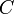 .
.
[edit] Key constraints and functional dependencies
One of the simplest and most important types of relation constraints is the key constraint. It tells us that in every instance of a certain relational schema the tuples can be identified by their values for certain attributes.
- Superkey
- A superkey is written as a finite set of attribute names.
- A superkey
 holds in a relation
if:
holds in a relation
if:
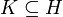 and
and- there exist no two distinct tuples
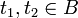 such that
such that ![t_1[K] = t_2[K]](relation1_files/cc2de0d20b778525381ab26b44ab9706.png) .
.
- A superkey holds in a relation universe
if it holds in all relations in .
- Theorem: A superkey
holds in a relation universe
over
if and only if
and
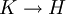 holds in .
holds in . - Candidate key
- A superkey
holds as a candidate key for a relation universe
if it holds as a superkey for
and there is no proper
subset of
that also holds as a superkey for .
- Functional dependency
- A functional dependency (FD for short) is written as
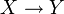 for
for 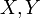 finite
sets of attribute names.
finite
sets of attribute names. - A functional dependency
holds in a relation
if:
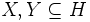 and
and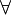 tuples ,
tuples ,
![t_1[X] = t_2[X]~\Rightarrow~t_1[Y] = t_2[Y]](relation1_files/bc9c88afb773362b701adf7a8f5d3853.png)
- A functional dependency
holds in a relation universe
if it holds in all relations in .
- Trivial functional dependency
- A functional dependency is trivial under a header if it holds in all
relation universes over .
- Theorem: An FD
is trivial under a header
if and only if
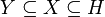 .
. - Closure
- Armstrong's
axioms: The closure of a set of FDs
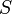 under a header ,
written as
under a header ,
written as 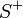 ,
is the smallest superset of
such that:
,
is the smallest superset of
such that:
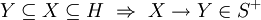 (reflexivity)
(reflexivity)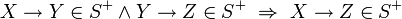 (transitivity)
and
(transitivity)
and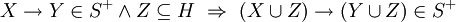 (augmentation)
(augmentation)
- Theorem: Armstrong's axioms are sound and complete; given a header
and a set
of FDs that only contain subsets of ,
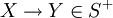 if and only if
holds in all relation universes over
in which all FDs in
hold.
if and only if
holds in all relation universes over
in which all FDs in
hold. - Completion
- The completion of a finite set of attributes
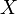 under a finite set of FDs ,
written as
under a finite set of FDs ,
written as 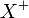 ,
is the smallest superset of
such that:
,
is the smallest superset of
such that:
- The completion of an attribute set can be used to compute if a certain dependency is in the closure of a set of FDs.
- Theorem: Given a set
of FDs,
if and only if
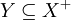 .
. - Irreducible cover
- An irreducible cover of a set
of FDs is a set
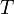 of FDs such that:
of FDs such that:
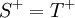
- there exists no
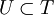 such that
such that 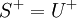
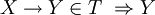 is a singleton set and
is a singleton set and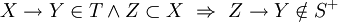 .
.
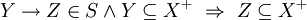
[edit] Algorithm to derive candidate keys from functional dependencies
INPUT: a set S of FDs that contain only subsets of a header H
OUTPUT: the set C of superkeys that hold as candidate keys in
all relation universes over H in which all FDs in S hold
begin
C := ∅; // found candidate keys
Q := { H }; // superkeys that contain candidate keys
while Q <> ∅ do
let K be some element from Q;
Q := Q – { K };
minimal := true;
for each X->Y in S do
K' := (K – Y) ∪ X; // derive new superkey
if K' ⊂ K then
minimal := false;
Q := Q ∪ { K' };
end if
end for
if minimal and there is not a subset of K in C then
remove all supersets of K from C;
C := C ∪ { K };
end if
end while
end
[edit] See also
|
[edit] References
- ^ "Derivability, Redundancy, and Consistency of Relations Stored in Large Data Banks", E.F. Codd, IBM Research Report, 1969
- ^ "A Relational Model of Data for Large Shared Data Banks", in Communications of the ACM, 1970.
- ^ White, Colin. In the Beginning: An RDBMS History. Teradata Magazine Online. September 2004 edition. URL: http://www.teradata.com/t/page/127057
- ^ Data Integration Glossary, U.S. Department of Transportation, August 2001.
- ^ E. F. Codd, The Relational Model for Database Management, Addison-Wesley Publishing Company, 1990, ISBN 0-201-14192-2
- ^ Codd, E.F. (1970). "A Relational Model of Data for Large Shared Data Banks". Communications of the ACM 13 (6): 377–387. doi:10.1145/362384.362685. http://www.acm.org/classics/nov95/toc.html.
- ^ David M. Kroenke, Database Processing: Fundamentals, Design, and Implementation (1997), Prentice-Hall, Inc., pages 130–144
[edit] Further reading
- Date, C. J., Darwen, H. (2000). Foundation for Future Database Systems: The Third Manifesto, 2nd edition, Addison-Wesley Professional. ISBN 0-201-70928-7.
- Date, C. J. (2003). Introduction to Database Systems. 8th edition, Addison-Wesley. ISBN 0-321-19784-4.
[edit] External links
| Wikimedia Commons has media related to: Relational models |
- Feasibility of a set-theoretic data structure : a general structure based on a reconstituted definition of relation (Childs' 1968 research cited by Codd's 1970 paper)
- The Third Manifesto (TTM)
- Relational Databases at the Open Directory Project
- Relational Model
- Binary relations and tuples compared with respect to the semantic web
| |||||||||||
| ||||||||||||||||||||